Nous vous rappelons que, afin de garantir l'accès de tous les inscrits aux salles de réunion, l'inscription aux réunions est gratuite mais obligatoire.
Inscriptions closes à cette réunion.
29 personnes membres du GdR ISIS, et 30 personnes non membres du GdR, sont inscrits à cette réunion.
Capacité de la salle : 60 personnes.
Journée inter-GdR ISIS et Robotique
29 septembre 2023 - Paris
Lieu
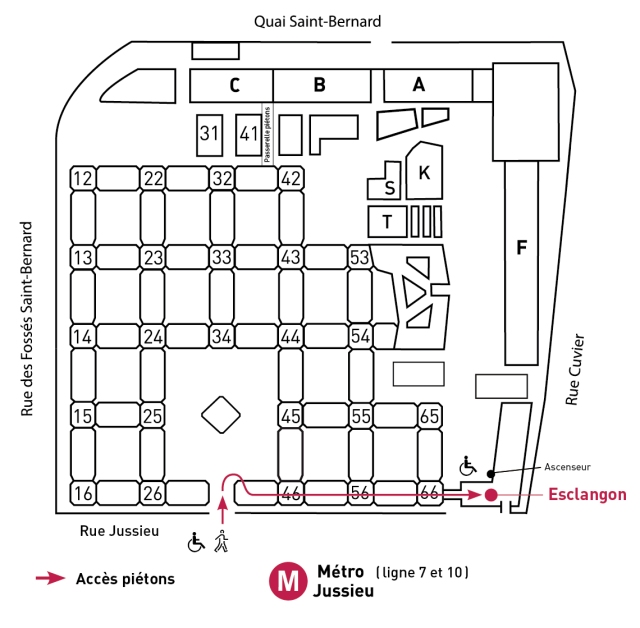
SORBONNE UNIVERSITÉ, Campus Université Pierre & Marie Curie, 4 place Jussieu, 75005, Paris
Bâtiment Esclangon, Amphi Durand (Lien vers plan)
Nombre de places : 60 participant(e)s (inscription gratuite mais obligatoire sur le site du GdR ISIS)
https://cnrs.zoom.us/j/92036220508?pwd=TW44S0YrYXBlRlA3RjdnV3NVbFNSUT09
ID de réunion: 920 3622 0508
Code secret: MF6tQ9
Guillaume Caron (CNRS-AIST JRL, UPJV MIS), Brahim Tamadazte (CNRS-SU ISIR), Nathanaël Jarassé (CNRS-SU ISIR), Pascal Vasseur (UPJV MIS), Franck Ruffier (CNRS-AMU ISM)
Les GdRs ISIS et Robotique s'associent pour l'organisation d'une journée de travail autour du calcul de pose 3D en vision par ordinateur. En effet, l'estimation précise de la pose 3D d'un objet (translations et rotations) à partir d'informations visuelles issues d'un capteur ou de plusieurs capteurs visuels, qu'ils soient 2D (caméras conventionnelles) ou 3D (caméras de profondeur, lidar, ...) reste une problématique scientifique ouverte malgré les énormes progrès réalisés dans le domaine dans les dernières décennies.
Le calcul de pose est une brique souvent essentielle de nombreux travaux de recherche en robotique pour la manipulation d'objets, la navigation, les tâches d'assemblage/désassemblage, mais aussi en réalité virtuelle, mixte ou augmentée, voire encore le recalage d'informations multimodales et le suivi visuel. Outre l'estimation de la pose 3D d'objets rigides, les travaux s'intéressant aux objets articulés ou déformables voient un nouvel engouement notamment avec le développement rapide de la robotique souple et la manipulation robotique des objets déformables.
Malgré les avancées constantes du domaine, des aspects fondamentaux des premiers temps à l'avènement de l'apprentissage profond, plusieurs verrous scientifiques restent d'actualité, à la fois sur les aspects de précision, de robustesse, de généralisation, de rapidité de calcul et aussi en termes d'exploitation des capteurs visuels émergents (nouvelles caméras RGB-D, caméras à événements, caméras plénoptiques, imagerie médicale, ...).
Le but de cette journée est de réunir les communautés de vision par ordinateur et de robotique pour aborder les dernières avancées scientifiques et applicatives de l'estimation de pose et discuter des problématiques scientifiques en suspens. La journée sera articulée autour d'exposés d'un panel d'orateurs invités et de présentations sélectionnées issues de l'appel à participation adressé aux deux communautés des GDRs ISIS et Robotique.
A noter que les résumés (1 page maximum) doivent être transmis avant le 25 août 2023 5 septembre 2023 aux organisateurs (cf. la section "contacts") afin d'avoir une meilleure couverture des thématiques (méthodes géométriques/apprentissage machines/hybrides, type de capteur utilisé, application, etc.).
Le GdR ISIS "Information, Signal, Image, Vision" est une structure d'animation du CNRS rassemblant plus de 4600 chercheurs, ingénieurs, techniciens et industriels. C'est dans le cadre du Thème B "Image et Vision", action spécifique "Vision guidée par les capteurs émergents" que cette journée thématique inter-GdR est organisée.
Le GdR-Robotique est fort de plus de 1200 chercheurs et ingénieurs relevant de différents établissements publics (universités, laboratoires de recherche, etc.) et privés. Il est organisé en plusieurs groupes de travail (GT) couvrant les grandes disciplines de la robotique. Chaque GT organise une ou plusieurs rencontres annuelles pour discuter et échanger des dernières avancées de la robotique.
10h00 - "RoCNet: 3D Robust Registration of Point-Clouds using Deep Learning", exposé invité de Karim Slimani (ISIR UMR 7222, CNRS, Sorbonne Université, Inserm)
10h35 - "Advancing Wide Baseline Scene Registration with Structural Vanishing Points", contribution d'Abdelkarim Elassam, Gilles Simon et Marie-Odile Berger (Inria)
11h00 - "Pointless bundle adjustment with hessian propagation for large-scale SfM", contribution d'Ewelina Rupnik et Marc Pierrot-Deseilligny (LaSTIG, UGE, IGN-ENSG)
11h25 - "H3WB: Human3.6M 3D WholeBody Dataset and Benchmark", exposé invité de Yue Zhu (IMAGINE/LIGM, Marne-la-vallée)
14h00 - "Localisation visuelle pour la surveillance à long terme des grands fonds", exposé invité de Clémentin Boittiaux (Ifermer Toulon)
14h35 - "Odométrie visuelle à partir d'une caméra light-field", contribution de Mohamad Al Assaad, Stéphane Bazeille, Christophe Cudel (UHA IRIMAS, équipe IMITAS)
15h30 - "Shape tracking and servoing of deformable objects from 2D or 3D cameras", exposé invité de Mohammadreza Shetab-Bushehri (Institut Pascal, Clermont-Ferrand)
16h05 - "Téléopération d'un bras manipulateur collaboratif par un couplage physique humain-robot", contribution d'Alexis Poignant, Nathanaël Jarrassé, Guillaume Morel (ISIR, CNRS, SU Paris)
Titre :
RoCNet: 3D Robust Registration of Point-Clouds using Deep Learning
Résumé :
Il s'agit d'une méthode fondée sur de l'apprentissage profond pour le recalage de deux nuages de points. RoCNet comprend trois modules principaux : i) un descripteur fondé sur des graphes convolutifs combinés à un mécanisme d'attention. ii) un algorithme de transport optimal pour estimer l'appariement des points. iii) Enfin, un RANSAC est utilisé pour calculer la transformation rigide entre les deux nuages de points en fonction des correspondances prédites par le réseau.
Titre :
Shape tracking and servoing of deformable objects from 2D or 3D cameras
Résumé :
Deformable object manipulation is extremely challenging due to the deformable object's highly complex and dynamic behavior. To succeed, one has to solve two open problems: (i) shape tracking of deformable objects and (ii) shape servoing of deformable objects. Shape tracking should be able to infer the deformable object's shape accurately at real-time. Shape servoing should be able steer the deformable object's shape to a desired shape. We propose several geometric real-time approaches to address these two open problems. Proposed approaches can handle linear, thin-shell or volumetric deformable objects, and work with 2D or 3D cameras. Proposed approaches are validated through various experiments with various objects.
Titre :
Localisation visuelle pour la surveillance à long terme des grands fonds
Résumé :
Pour explorer les profondeurs de l'océan, nous dépendons fortement des véhicules sous-marins. Cependant, l'exploration en haute mer avec des véhicules téléopérés est souvent excessivement coûteuse et chronophage, car elle nécessite que le navire soit mobilisé pendant toute la durée de la plongée. Il est donc nécessaire de développer des systèmes autonomes pour réaliser efficacement ces tâches exploratoires en utilisant moins de temps et de ressources. Le succès de ces véhicules repose sur leur capacité à déterminer avec précision leur emplacement dans leur environnement, un processus appelé localisation. Cependant, en raison de la forte atténuation des ondes électromagnétiques dans l'eau, les systèmes de navigation par satellite ne fonctionnent pas dans les environnements sous-marins. De plus, bien que les capteurs acoustiques soient traditionnellement utilisés pour la localisation sous-marine, ils ne sont pas toujours disponibles et peuvent manquer de la précision nécessaire pour certaines applications critiques, telles que la cartographie d'une zone précise. En revanche, les observations visuelles capturées par les véhicules sous-marins offrent une alternative prometteuse, permettant potentiellement une localisation plus précise. Ainsi, cette présentation couvrira les éléments suivants : 1) la création d'un jeu de données pour la localisation visuelle sous-marine, 2) l'élaboration d'une nouvelle fonction de coût destinée à la régression de la pose dans le contexte du deep learning, 3) une étude de la performance des algorithmes de localisation visuelle sur le jeu de données présenté.
Titre :
H3WB: Human3.6M 3D WholeBody Dataset and Benchmark
Résumé :
Human body pose estimation is a well studied topic in computer vision because of the numerous applications it enables from body motion prediction and action recognition to augmented reality. In 2D, the task consists in detecting a set of keypoints corresponding to body parts and has been so successful lately that benchmarks on whole-body skeletons (including detailed keypoints on the hands and facial landmarks) are nearly saturated. In 3D, the problem gets more complex because of several factors. First, the perspective-scale ambiguity makes it an ill-posed problem. Second, and more importantly, data acquisition of 3D human body skeletons has proven difficult since it requires a dedicated motion capture setup and is mostly limited to controlled environments. In practice, 3D human body pose datasets are thus restricted to simple skeletons with very few keypoints and this in turns limits their potential applications. To enable further research on this subject, we present in this work an extension of the Human3.6m dataset to a wholebody skeleton of 133 keypoints (including 68 for the face, 42 for the hands) in 3D, enabling detailed pose modeling. To build these new annotations, we leverage several complementary processes from multi-view geometry, masked auto-encoders and conditional diffusion models, leading to 100k images and their associated 133 keypoints in 3D. We propose a benchmark consisting of three tasks: complete 2D skeleton to 3D skeleton lifting, incomplete 2D skeleton to complete 3D skeleton lifting, monocular image to complete 3D skeleton regression ; and propose several baselines for each of these.
Titre :
Pointless bundle adjustment with hessian propagation for large-scale SfM
Résumé :
In precision large-scale 3D mapping the orientations of images must be known precisely. By image orientation we mean the extrinsic parameters, also referred to as the camera pose and the intrinsic parameters. In this research we focus on camera pose estimation with global motion structure-from-motion (SfM). Global motion methods (often referred to as global motion averaging ) use elementary relative motions to resolve the camera poses in a global manner. Excluding features from computing the global poses reduces the computation time significantly. Moreover, because the poses are computed all at once, motion averaging surmounts the pitfall of incremental methods [3] where errors accumulate all along the initialisation step, and lead to trajectory drift. However, such methods give rise to new challenges. First, by relying exclusively on pairs or triplets of images, motion averaging methods ultimately renounce higher observation redundancy (i.e., long feature tracks), which we know negatively impacts both the camera pose estimation robustness and precision. Second, once the relative poses computed, the structure used in the calculation is discarded, and all relative relationships, whether derived from erroneous observations or not, are treated equally. Consequently, global approaches are considered as good SfM initialisations but never considered optimal and are systematically followed by a BA routine. This refinement is crucial because for a given acquisition it finds the most optimal camera poses by taking simultaneously all images and image features into account. Yet, as the image number grows, the memory requirements increase quadratically while the time requirements increase cubically. Solving such large non-linear least squares problems simultaneously for all images with the golden standard Levenberg-Marquardt becomes prohibitive. Our aim is to upgrade the motion global SfM from being merely an initialiser towards an optimal method. To this end we wed the global motion SfM with the traditional bundle adjustment refinement and distill what is best about them, i.e. the speed of the global approach
and the precision of the BA.
Titre :
Advancing Wide Baseline Scene Registration with Structural Vanishing Points
Résumé :
Matching and registering two views of a scene are critical in computer vision, especially for tasks like 3D reconstruction and localization. However, this becomes exceptionally challenging under varying environmental conditions or distant viewpoints. Despite extensive research, wide baseline view registration remains difficult. Our prior work, CollabVP, introduced a method for detecting Vanishing Points (VPs) and generating scene structure masks, mainly for VP detection. This study uses these masks to robustly match VPs, improving the relative camera orientation in wide-baseline views. Furthermore, we employ VPs to orthorectify scene structures and enhance key point matching, resulting in more accurate camera translation estimates than traditional methods. Comprehensive evaluations across diverse scenarios demonstrate our approach's superiority, even outperforming the state-of-the-art SuperGlue method in challenging conditions.
Titre :
Odométrie visuelle à partir d'une caméra light-field.
Résumé :
Dans cette présentation nous allons présenter, les travaux récents de l'Université de Haute-Alsace dans le domaine de l'odométrie visuelle a partir d'imagerie plénoptique. Ces travaux se basent sur un algorithme d'odométrie visuelle monoculaire développé dans l'équipe [8] et qui a été étendu aux caméras light-field. Nous avons montré que la phase de calibration peut être simplifiée par rapport aux méthodes souvent utilisés [9]. Nous avons également proposé une approche qui permet de réinvestir la plupart des opérateurs des traitement d'images classiques sur des images quasi-brutes, ce qui simplifie la détection des «keypoints» dans des images, sans redévelopper des détecteurs spécifiques aux caméras plénoptiques [10]. Les «keypoints» peuvent ensuite être reprojetés dans un plan virtuel de manière a réutiliser les méthodes conventionnelles de calculs de matrices de transformations géométriques. Cette approche conduit à déterminer la rotation et la translation normalisée entre les deux repères de prises de vues. L'apport de la caméra plénoptique est d'exploiter les informations 3D de la scène pour atteindre le facteur d'échelle et ensuite dénormaliser la translation. Avec ce principe, il est possible de réutiliser les algorithmes de navigation visuelle existant avec un minimum d'adaptation. Notre méthode a été évaluée a partir de données réelles obtenues avec un robot muni d'une caméra light-field et d'une caméra monoculaire standard. Nous comparons notamment les performances des trajectoires obtenues.
Titre :
Téléopération d'un bras manipulateur collaboratif par un couplage physique humain-robot
Résumé :
Les interfaces corps-machine d'assistance [1] sont des systèmes connectés au corps afin de remplacer ou d'augmenter les capacités d'un opérateur. Ces systèmes sont généralement contrôlés par des commandes de type position-vitesse, comme des joysticks. Cependant, ces commandes sont moins intuitives et performantes que des commandes de type position-position, tels que des systèmes maitre-esclave, complexes à mettre en oeuvre.
Il existe cependant une autre commande position-position utilisée depuis de nombreuses années : les pointeurs, qui, attachés par exemple à la tête [2], permettent de "téléopérer" un stylo ou un clavier d'ordinateur. Ces couplages physiques, entre l'opérateur et son outil, sont intuitifs mais difficilement instrumentables.
Inspiré de ces pointeurs, nous proposons de créer un lien opérateur-robot virtuel basé sur une relation géométrique physique, reconfigurable par une commande position-vitesse. Ce lien virtuel est alors visualisé par l'opérateur dans un casque de réalité augmenté afin de supprimer les délais de perception de la commande, permettant d'obtenir un système hybride position-position/vitesse permettant de réaliser des tâches d'assistances, notamment pour des manipulateurs de fauteuils ou une troisième main (une vidéo illustratrive peut être trouvée à https://www.youtube.com/watch?v=EgwzT784Fws).
Date : 2023-09-29
Lieu : Bâtiment Esclangon, Amphi Durand, 4 place Jussieu, 75005, Paris
Thèmes scientifiques :
B - Image et Vision
Inscriptions closes à cette réunion.
(c) GdR IASIS - CNRS - 2024.
{kind=link}