Capteurs d'Images Intelligents
Nous vous rappelons que, afin de garantir l'accès de tous les inscrits aux salles de réunion, l'inscription aux réunions est gratuite mais obligatoire.
Inscriptions closes à cette réunion.
Inscriptions
8 personnes membres du GdR ISIS, et 1 personnes non membres du GdR, sont inscrits à cette réunion.
Capacité de la salle : 30 personnes.
Annonce
Réunion commune aux GdR ISIS et SOC/SIP
Organisateurs : Stéphane Guyetant (CEA LIST) et Michel Paindavoine (UB LEAD)
De nos jours, les nouvelles technologies de la microélectronique associées à des méthodologies d'adéquation algorithme-architecture permettent l'implantation d'algorithmes complexes de traitement de l'image sur des systèmes embarqués. Ainsi, dans le domaine des capteurs d'image CMOS, de nouveaux dispositifs ont vu le jour qui intègrent directement dans le plan focal (ou près du plan focal) des algorithmes complexes de traitement et d'analyse de l'image, comme par exemple l'extraction de caractéristiques pour la reconnaissance de formes.
L'objectif de cette journée qui fait suite à la journée du 14/12/2009 est de présenter les progrès des dernières recherches sur les capteurs d'image intelligents.
Programme
Matin : 10h-13h
- Réduction du flot de données de sortie des imageurs CMOS par Hawraa AMHAZ, Gilles SICARD, INP/UJF TIMA Grenoble.
- IcyCAM : un circuit « système sur puce » QVGA pour les applications de vision par Pierre-François Rüedi, Pascal Heim, Stève Gyger, François Kaess, Claude Arm, Ricardo Caseiro, Jean-Luc Nagel, Silvio Todeschini, CSEM Neuchatel.
- Les applications de l'imagerie rapide par Wilfried Uhring, ENSPS - IneSS Strasbourg.
- Capteurs d'images CMOS à réponse invariante à la température par Hakim ZIMOUCHE, Gilles SICARD, INP/UJF TIMA Grenoble.
- A Novel 3D Architecture for High Dynamic Range Image Sensor and on-Chip Data Compression par Arnaud Peizerat et Antoine Dupret CEA LETI, Grenoble.
Après midi : 14h-17h
- Smart caméra stéréo haute vitesse pour la mesure par vision des déformations de robots parallèles rapides par Frantz Pélissier et François Berry, LASMEA, Clermont-Ferrand.
- Conception d'une rétine intelligente basse consommation en vue d'une intégration en technologie 3D par Stéphane Chevobbe (CEA LIST).
- Identification locale du flou à partir d'une seule image par Pauline Trouvé (ONERA/DTIM), Frédéric Champagnat (ONERA/DTIM), Guy Le Besnerais (ONERA/DTIM), Jérôme Idier (IRCCyN).
- Système de traitement d'image embarqué de détection, suivi et stabilisation de visages par Nicolas Gourier, John-Alexander Ruiz-Hernandez, Claudine Combe, Equipe PRIMA de l'INRIA Rhône-Alpes.
- Discussion et Synthèse de la Journée.
Résumés des contributions
Réduction du flot de données de sortie des imageurs CMOS
Hawraa AMHAZ, Gilles SICARD, INP/UJF TIMA Grenoble
Le traitement d'images classique est basé sur l'évaluation des données délivrées par un système de capteur de vision sous forme d'images. L'information lumineuse captée est extraite séquentiellement de chaque élément photosensible (pixel) de la matrice avec un certain cadencement et à fréquence fixe. Ces données, une fois mémorisées, forment une matrice de données qui est réactualisée de manière exhaustive à l'arrivée de chaque nouvelle image. De fait, le système ne prend pas en compte le fait que l'information stockée ai changé ou non par rapport à l'image précédente. En effet, le nombre d'images par seconde est tel qu'il y a, dans beaucoup d'applications, de forte chance pour que cette information n'est pas changée. Ceci nous mène donc, selon « l'activité » de la scène filmée à un haut niveau de redondances temporelles. De la même manière, la méthode de lecture usuelle ne prend pas en compte le fait que le pixel en phase de lecture ai la même valeur ou non du pixel voisin lu juste avant. Cela rajoute aux redondances temporelles un taux de redondances spatiales plus ou moins élevé selon la fréquence spatiale de la scène filmée. Notons que dans ce cas de lecture, la largeur de la bande passante de sortie du capteur est partagée également entre tous les pixels de la matrice. Les travaux présents dans la littérature proposent plusieurs solutions à cette problématique, mais en général, ces solutions exigent de gros sacrifices au niveau de surface du pixel, vu qu'elles implémentent des fonctions électroniques complexes in situ. Dans cette thèse, nous avons décidé de travailler sur des solutions pour réduire les redondances temporelles et spatiales tout en conservant des tailles pixels qui respectent les contraintes industrielles. Concernant la réduction des redondances spatiales, nous proposons de profiter du fait que les informations lumineuses sont stockées dans les amplificateurs colonnes pendant le temps de lecture d'une ligne de la matrice, pour comparer les valeurs de luminosités de deux pixels voisin. Cette comparaison permet de contrôler les pixels à digitaliser et gagner ainsi soit au niveau de la consommation (moins de conversion à faire), soit sur le débit d'image (1). L'avantage le plus important de cette méthode est qu'elle est indépendante du type du pixel et qu'elle n'impose aucune contrainte sur sa surface. Des simulations Matlab ont été faites afin d'évaluer l'efficacité de la méthode et le circuit est prêt à partir en fabrication. Au niveau de la réduction des redondances temporelles, nous proposons de regrouper les pixels de la matrice en sous blocs de 4x4 pixels. Chacun de ces sous blocs génère, en continu, et en même temps que les informations lumineuses de chaque pixel, une tension qui représente la moyenne des informations lumineuses du sous bloc. La lecture de cette sous matrice et la comparaison avec la sous matrice de l'image précédente, va permettre de déterminer les adresses des blocs de pixels à lire. Des simulations Matlab ont été faites pour évaluer l'efficacité de la méthode ainsi que pour préciser la taille des sous-blocs. Un circuit de test est actuellement en cours de conception.
(1) H. Amhaz, G. Sicard, « X-axis Spatial Redundancy Supression : Contribution to the Integration of Smart Reading Techniques in a Standard CMOS Vision Sensor », 17th IEEE International Conference on Electronics, Circuits and Systems (ICECS'10), Athens, Greece, 12-15 December 2010.
IcyCAM : un circuit « système sur puce » QVGA pour les applications de vision
Pierre-François Rüedi, Pascal Heim, Stève Gyger, François Kaess, Claude Arm, Ricardo Caseiro, Jean-Luc Nagel, Silvio Todeschini, CSEM Neuchatel
Le CSEM a développé un circuit intégré spécifique conçu pour les applications de vision dans des environnements dont l'illumination n'est pas contrôlée. Son capteur de 320 par 240 (QVGA) pixels, basé sur un codage logarithmique du temps d'intégration, offre une gamme dynamique extrêmement grande (132 dB), permettant ainsi l'acquisition d'images de qualité même dans des environnements soumis à des variations rapides d'intensité lumineuse. Le calcul de l'amplitude et de la direction du contraste implémenté dans le chemin de lecture des données facilite l'analyse de données visuelles. De plus, le processeur Icyflex de 32 bits cadencé à 50 MHz bénéficie d'une unité de traitement graphique dédiée pour le décharger des tâches répétitives (par exemple la différence entre 2 images). Le système sur puce comprend également 128 Koctets de SRAM et peut être connecté à une SDRAM externe.
Ce circuit, nommé Icycam, est optimisé pour faciliter l'analyse d'images et la prise de décision. L'architecture de son capteur alliée à une représentation des données adéquate contribue à maximiser la robustesse et minimiser les besoins en puissance de calcul. De plus, l'intégration d'un système complet sur un unique circuit minimise les coûts et la consommation. Icycam est programmable en C et en assembleur pour implémenter des algorithmes de vision et des tâches de contrôle. Intégré dans une technologie CMOS de 0.18 um, il consomme 80 mW et a une surface de 44 mm2.
Les applications visées se trouvent dans les domaines de l'automobile, de la sécurité, du contrôle industriel et de la robotique.
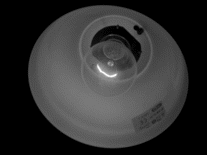
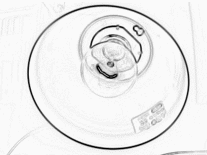

Images : Cliché d'une lampe de bureau allumée montrant la luminance, l'amplitude du contraste et la direction du contraste représentée par des couleurs.
Les applications de l'imagerie rapide
Wilfried Uhring, ENSPS - IneSS Strasbourg
L'imagerie rapide connait depuis un peu plus de 10 ans une grande évolution et voie ses domaines d'applications s'élargir de jours en jours. Cette révolution est principalement due à la réalisation de capteurs optoélectroniques rapides à l'aide des technologies CMOS. Ces capteurs permettent de réaliser des caméras vidéo pouvant prendre de 1 000 à 1 000 000 d'images pas seconde, des caméras capables de mesurer des temps de vol de photon avec une résolution temporelle de quelques dizaines de picoseconde ou bien encore des caméras qui captures des événements lumineux avec un débit qui approche le Téra échantillon par seconde. Dans ce séminaire nous nous intéresserons brièvement à l'architecture de ces capteurs et nous intéresserons plus particulièrement à leurs applications. Nous voyagerons à travers les applications de cinématographie ludique, les études de mécanique des solides et des fluides, les mesures de scène en 3D par mesure de temps de vol, les identifications de bactérie par fluorescence résolue en temps, les applications d'imagerie médicale en neuroscience cognitive en passant par les applications de vélocimétrie en détonique.
Capteurs d'images CMOS à réponse invariante à la température
Hakim ZIMOUCHE, Gilles SICARD , INP/UJF TIMA Grenoble
Les capteurs d'image CMOS sont actuellement de plus en plus utilisés dans des applications industrielles : la surveillance, la défense, le médical, l'automobile, etc. Dans ces divers domaines, les capteurs d'image CMOS sont exposés régulièrement à des grandes variations de température. Dans l'automobile par exemple, la variation de température admise est de -30°C à 125°C. La sensibilité de ces capteurs d'image CMOS aux variations de température, limite actuellement leurs applications. Jusqu'à présent, aucune solution intégrée n'a été proposée. Afin de remédier à ce défaut, nous travaillons dans le cadre de cette thèse sur diverses méthodes de compensation en température basées sur différentes structures innovantes. Ces méthodes de compensation sont intégrées au sein du capteur afin de gagner en consommation d'énergie et en temps d'exécution. Après avoir étudié l'influence de la température sur les paramètres du transistor et sur les différentes parties (pixel et amplificateur colonne) de deux types d'imageurs (capteur standard ou « à intégration » et capteur logarithmique ou « à fonctionnement continue »), nous avons proposé plusieurs méthodes de compensation en température pour ces deux types d'imageurs. La première méthode utilise une entrée au niveau du pixel qui est modulée en fonction de l'évolution de la température [1]. La deuxième méthode utilise la technique dite « ZTC » (Zero Temperature Coefficient) [2]. La troisième méthode est basée sur le principe de fonctionnement des systèmes de Tension de Référence de type « Bandgap » [3]. Avec ces méthodes de compensation en température, nous obtenons une bonne stabilité de la tension de sortie du capteur dans la gamme de température de -30°C à 125°C. Les deux premières méthodes vont être testées grâce à un circuit qui vient de revenir de fabrication et la dernière va être mise en oeuvre dans un circuit en cours de conception.
[1] H. Zimouche, G. Sicard, « Standard Linear CMOS Image Sensor Insensitive to Temperature Variations » The 8th IEEE International NEWCAS'10 Conference, Montreal, Canada, 20-23 June , 2010
[2] H. Zimouche, G. Sicard, « Integrated Temperature Compensation Scheme for a Standard Linear CMOS Vision Sensor» 6th IEEE Conference on Ph.D. Research in Microelectronics & Electronics (PRIME'10), Berlin, Germany, 18-21 July 2010.
[3] H. Zimouche, G. Sicard, « Temperature Compensation Method for Logarithmic CMOS Vision Sensor Using CMOS Voltage Reference Bandgap Technique», 17th IEEE International Conference on Electronics, Circuits and Systems (ICECS'10), Athens, Greece, 12-15 December 2010.
A Novel 3D Architecture for High Dynamic Range Image Sensor and on-Chip Data
Compression par Arnaud Peizerat et Antoine Dupret CEA LETI, Grenoble
The intensity of light of natural scenes has a dynamic range that can be over 120 dB. Classical 3T or 4T pixel architectures cover only 60-70 dB. Current works on CMOS image High Dynamic Range (HDR) sensor have led to dynamic range over 120dB at the expense of more complex architectures. In some cases, this leads to lower Fill Factor or larger pixel pitch. The emergence of 3D circuits may help to overcome those limitations. Moreover large scale image sensor must face the increase in required bandwidth and this problem becomes more acute with HDR images. In this paper, we propose an original architecture for extending the image sensor dynamic range together with a local compression of data for a 3D circuit image sensor. The targeted circuit is composed of 2 vertically stacked wafers with a pixel size below 5µmx5µm. The proposed technique for HDR is based-on a floating point coding. A first data reduction is obtained by applying a common 4-bit exponent to each block of pixels, referred to as macro-pixel. For each macro-pixel, the optimal exposure is set by a dynamic adaptation of the integration time according to the received photon quantity. It theoretically allows reaching a dynamic range equivalent to about 20 bits. Simulation results show images with very few artefacts. In order to further reduce the amount of data, an on-chip data compression is performed at the macro-pixel level. Indeed, a compact compression architecture implements a compression algorithm on each block of macro-pixels. Only the mantissa array is compressed and the reduced exponent array with an exponent per macro-pixel is stored. This new concept features a good image quality (PSNR of about 40 dB) and a high dynamic range (120 dB) and shows a compression ratio over 75%, while maintaining a complexity compatible with 3D circuits. Finally, further work such as A/D conversion will be discussed.
Smart caméra stéréo haute vitesse pour la mesure par vision des déformations de robots parallèles rapides
Frantz Pélissier et François Berry, LASMEA, Clermont-Ferrand
Dans le cadre du projet ANR Virago dont le but est la mesure par vision des déformations de robots parallèles rapides, une smart caméra stéréo haute vitesse a été développée. Cette caméra appelée BiSeeMos intègre un FPGA haute densité ainsi que 2 imageurs CMOS développés par la société PhotonFocus. Elle a été conçue pour tester et valider des algorithmes de stéréovision en temps réel jusqu'à 160 images par secondes avec une résolution maximale de 1024 par 1024 pixels. Une reconstruction par stéréovision dense utilisant l'algorithme Census a été implémentée dans la plateforme pour démontrer ses capacités temps réel.
Conception d'une rétine intelligente basse consommation en vue d'une intégration en technologie 3D
Stéphane Chevobbe (CEA LIST)
Une rétine intelligente est un dispositif de vision capable de réaliser l'acquisition d'image plus un ensemble de fonction de traitement d'image. Ce concept bio-inspiré, existant depuis les années 80, a permis de montrer des avantages tel que l'amélioration de la vitesse de traitement, des capacités d'auto-adaptation (temps d'exposition, sensibilité, dynamique et offset), une faible consommation d'énergie, une forte potentialité d'intégration par rapport aux systèmes de vision classiques constitués d'une caméra et d'un processeur de traitement. Plusieurs travaux de recherche ont déjà amené à la conception de rétines intelligentes, complètement analogique, mixte analogique-numérique, dédiée à une application ou programmable. Cependant, ces rétines artificielles souffrent de limitations de résolution (à cause de l'intégration des processeurs dans le pixel), de précision (à cause de la faible surface d'intégration silicium) et de flexibilité.
Dans ce contexte, le projet ANR PACS a eu pour objectif de développer un nouveau modèle de rétine intelligente CMOS, qui surclasse les technologies actuelles, en intégrant au sein d'un unique composant une architecture de calcul performante et flexible capable de supporter des traitements d'images temps-réel évolués, et une matrice de pixel couplé à des éléments de traitements analogiques simples. A terme, la rétine intelligente qui utilisera ce modèle sera à la fois très compacte, de faible consommation, et facilement programmable pour permettre le développement de produits basés sur l'analyse vidéo temps-réel.
Identification locale du flou à partir d'une seule image
Pauline Trouvé (ONERA/DTIM), Frédéric Champagnat (ONERA/DTIM), Guy Le Besnerais (ONERA/DTIM), Jérôme Idier (IRCCyN)
Une image numérique présente souvent un flou variable spatialement, généralement à cause de déplacements des objets de la scène durant le temps d'acquisition, ou de l'écart de position de ces objets avec le plan de mise au point (défocalisation). Tout en réduisant la qualité de l'image, ce flou contient des informations sur le mouvement ou la position des objets de la scène. L'identification locale de la FEP (Fonction d'Etalement de Point) image permet donc à la fois d'extraire une information de profondeur ou de vitesse sur chaque région de la scène, et de construire une image de meilleure qualité grâce à un traitement de déconvolution local.
Nous nous intéressons à la conception d'un capteur imageur intelligent produisant outre l'image de la scène, une carte de profondeur ou de vitesse associée.
L'identification de la FEP et de la scène s'inscrit dans la problématique de déconvolution aveugle et les méthodes proposées dans la littérature font appel à des traitements complexes. Pour résoudre le problème, il est nécessaire d'exploiter une connaissance a priori. Par exemple, le flou peut être modélisé ou calibré en fonction d'un paramètre comme la vitesse ou la profondeur. S'il est possible de construire une famille finie de FEP potentielles, le problème d'identification revient alors à choisir localement la FEP dans cette famille. Cette approche sous-tend des travaux récents concernant la correction du bougé ou l'estimation de profondeur.
Nous proposons une méthode générale de sélection locale d'une FEP à partir d'une seule image et d'une famille de FEP potentielles. La sélection de la FEP, basée sur un calcul de maximum de vraisemblance, donne de bons résultats sur des images simulées et réelles pour des FEP de type flou de bougé ou défocalisation, et peut s'appliquer à une famille quelconque de flou.
Nous esquissons ensuite deux applications. D'abord nous proposons une technique de segmentation en profondeur ou en mouvement d'une scène à partir d'une vue unique. Ensuite nous présentons un calcul de borne de Cramer-Rao relative à l'estimation du paramètre de profondeur ou de mouvement. Une application potentielle de ce travail est la conception d'un capteur intelligent produisant une carte de profondeur ou de vitesse pour l'aide au déplacement autonome d'un drone.
Système de traitement d'image embarqué de détection, suivi et stabilisation de visages
Nicolas Gourier, John-Alexander Ruiz-Hernandez, Claudine Combe, Equipe PRIMA de l'INRIA Rhône-Alpes
Nous présentons les résultats du développement d'un système de traitement d'image embarqué de détection, suivi et stabilisation de visages fonctionnant en temps-réel pour les communications vidéo à base de pyramide de dérivées gaussiennes.
Depuis la dernière décennie, les dérivées gaussiennes se sont imposées comme une des méthodes fondamentales de description d'image, trouvant son usage dans la détection, le suivi, la reconnaissance d'objets et la reconstruction de scène. Base des descripteurs SIFT [Lowe 01] qui ont redéfini l'état de l'art du suivi et de la reconstruction, elles sont également utilisées dans les histogrammes de gradient [Dalal 05], la détection de visages [Ruiz 08], la reconnaissance d'objets et la détection de texte et de logos publicitaires. Cependant, pour une image de N pixels, les dérivées gaussiennes sont calculées en O(N^2) opérations, coûteuses et en virgule flottante. De ce fait, l'utilisation des filtres gaussiens pour des applications basées sur des traitements d'image embarqués a été considéré impossible.
Nous pouvons rendre le traitement embarqué en utilisant une pyramide à demi-octave invariante à l'échelle et à la rotation, calculée en O(N) opérations, proposée par [Crowley 84]. Une variante récente de cet algorithme permet de construire une pyramide composée de 2N échantillons à un coût de 18 opérations simples par pixel, en virgule fixe. Nous démontrons la possibilité d'embarquer ce descripteur pour des applications de vision par ordinateur de plus haut niveau telle que le suivi et la stabilisation de multiples visages pour réduire les besoins en bande passante lors de communications vidéo.